Yudit HOWTO
HOWTO Document List
You can see the howto documents in Yudit unicode editor if you type 'howto configure' in the command area of the editor window.
For your reference, I put the following documents on this server:
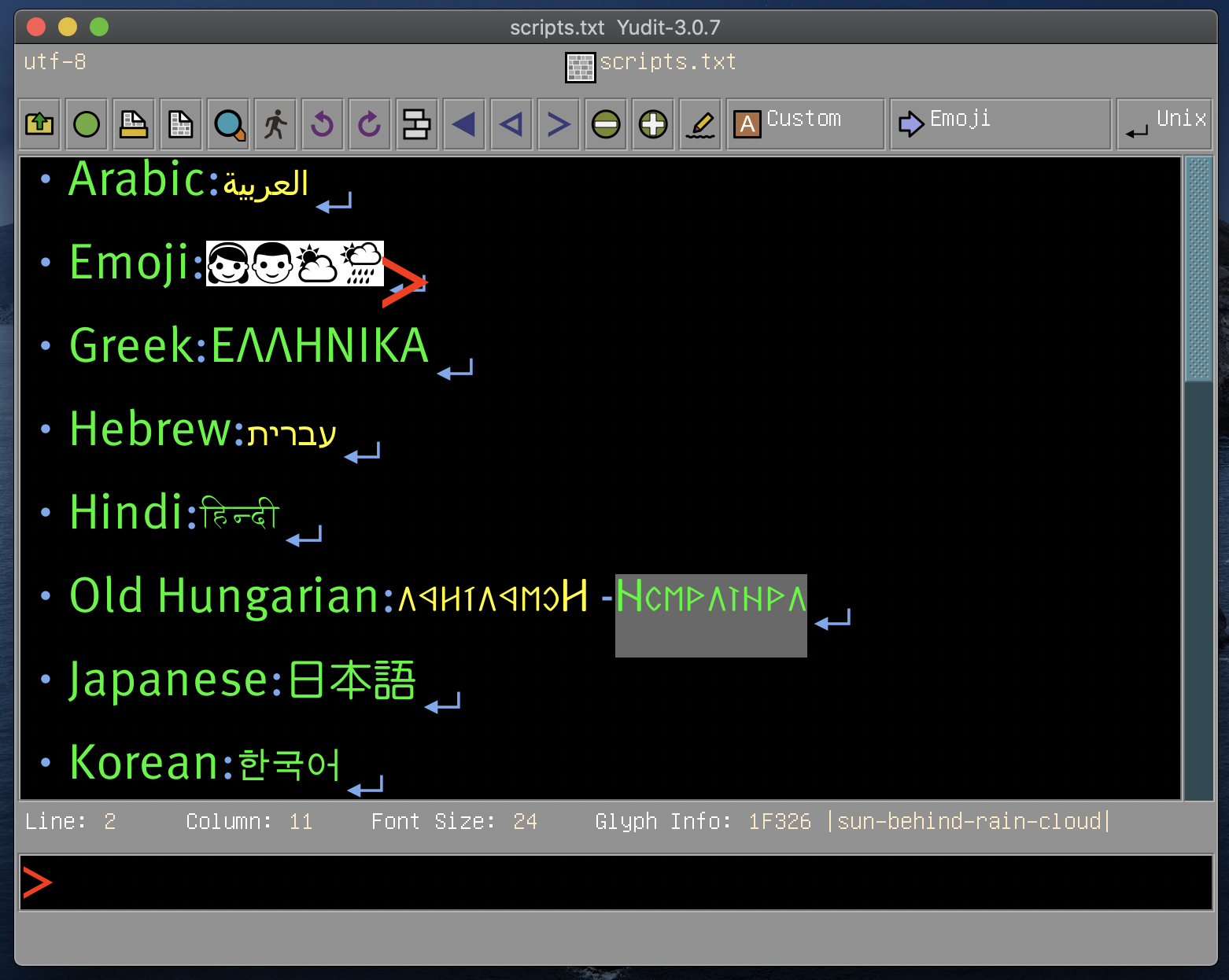
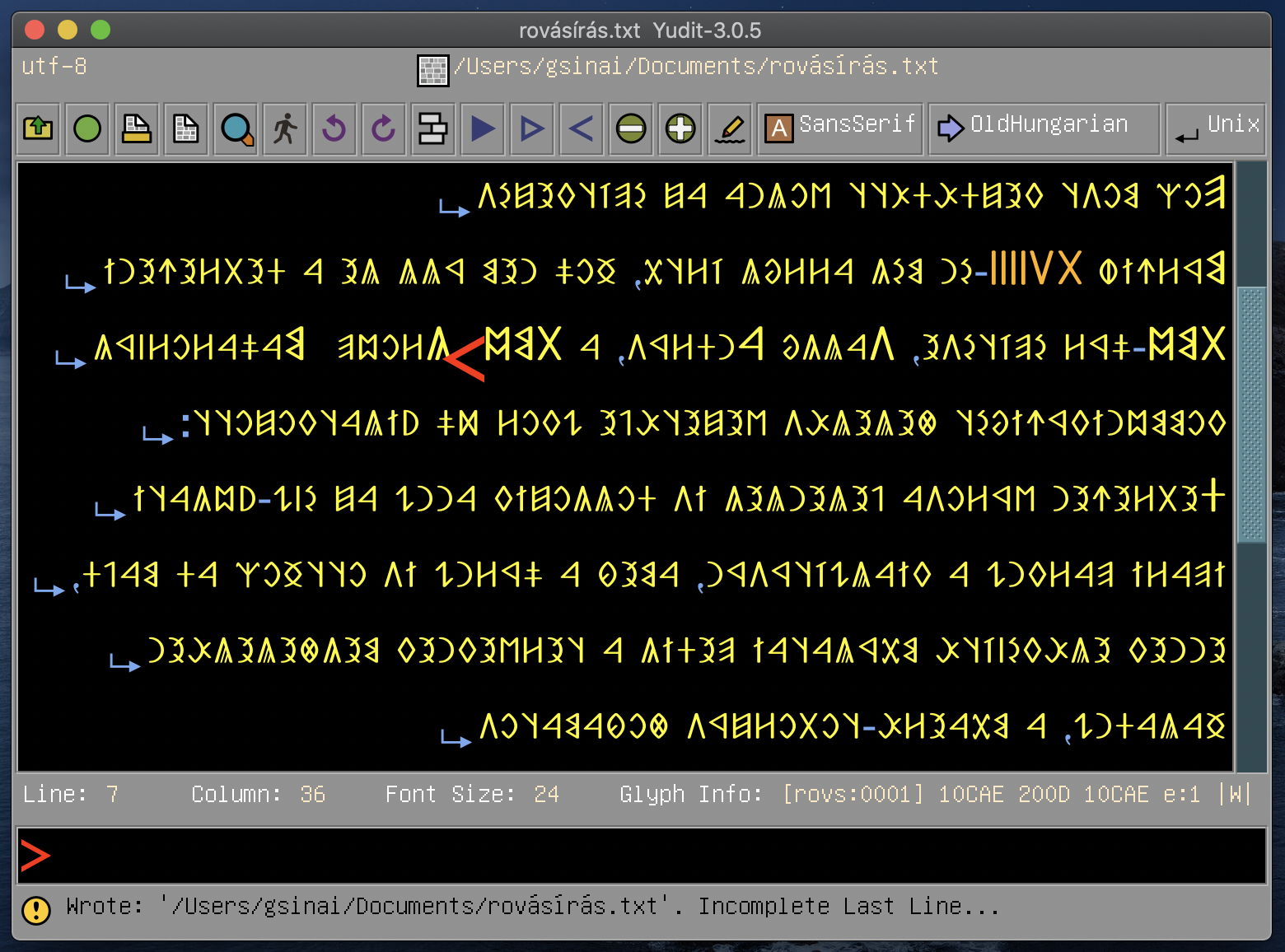
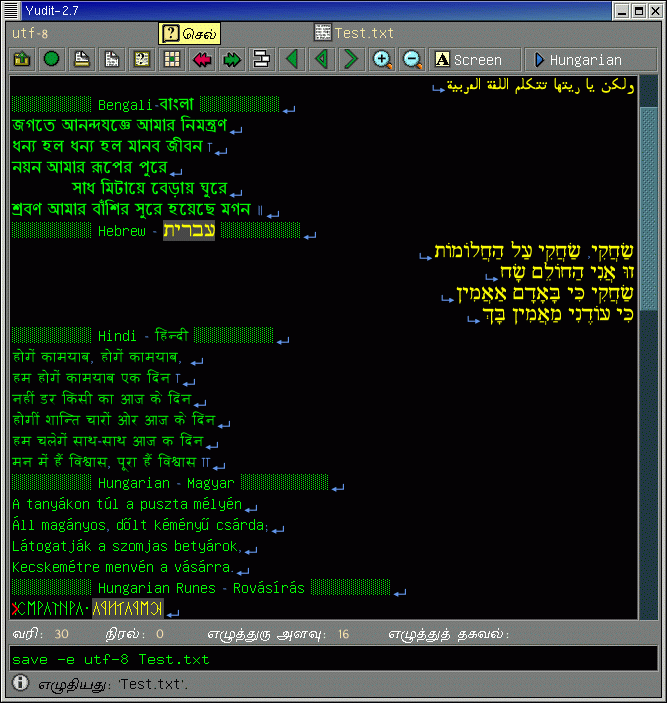
arabic, baybayin, berber, bidi, build, configure, devanagari, freehand, georgian, greekancient, japanese, keymap, malayalam, rovasiras, syntax, tamil, tibetan, vietnamese, windows
HOWTO keymap
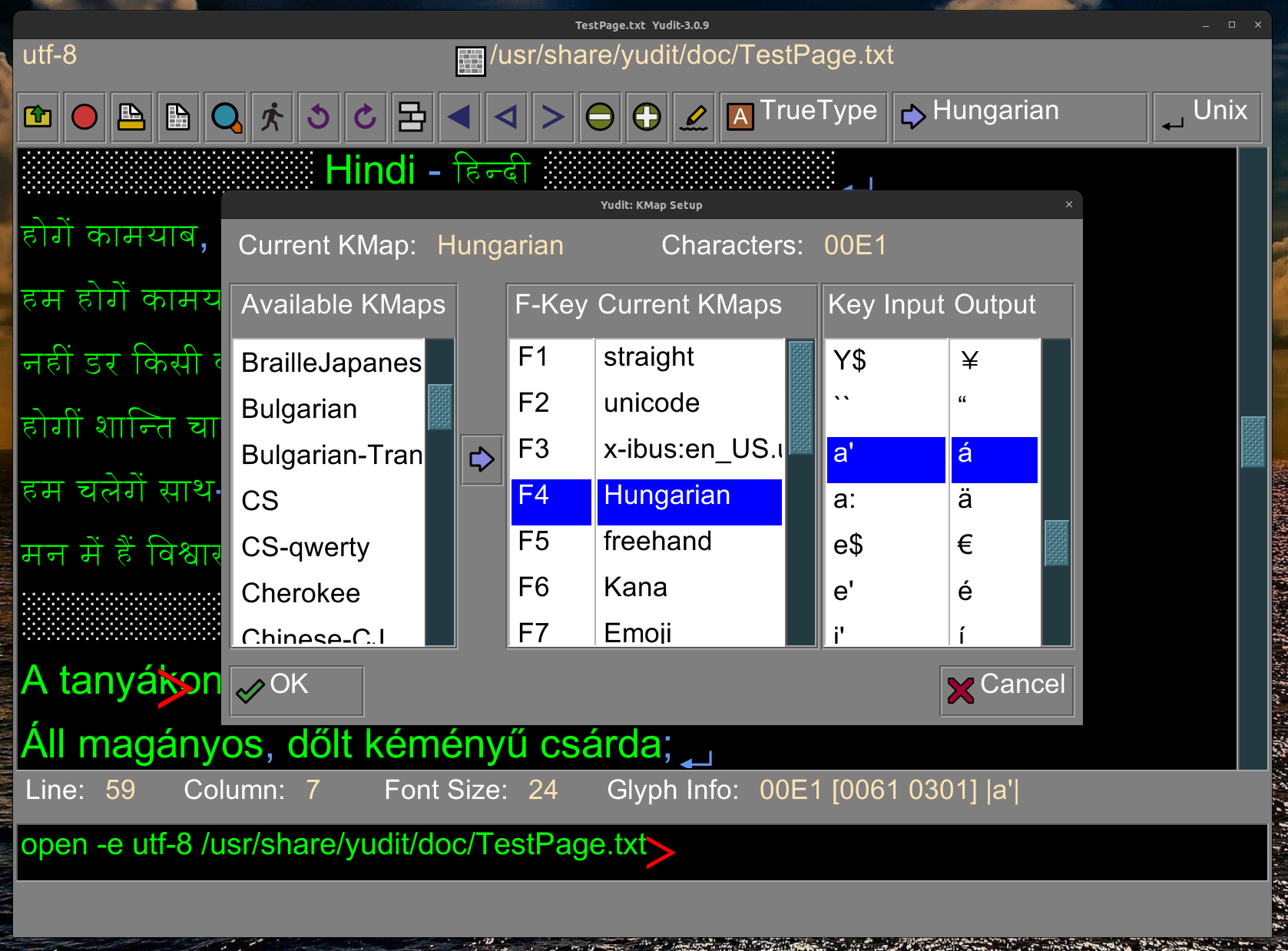
About .kmap files
Mind Tuning: The Unicode theory and Unicode-savvy text editors make
a clear (and useful) distinction among
1. the keyboard key(s) typed
2. the Unicode character(s) entered and stored in a file or
buffer, and
3. the glyph(s) (i.e. the graphic shapes) that are displayed.
Rendering: The mapping between the Unicode characters stored in a
file or buffer and the display of glyphs is handled by a Rendering
Engine, which can vary considerably in complexity, being fairly
straightforward for Latin scripts and very complex for Arabic or
Devanagari. Most users should be able to assume that the Rendering
Engine is taken care of.
Input Method: The mapping between the keyboard key(s) typed and the
Unicode character(s) entered in a file or buffer is defined by an
Input Method.
Defining Input Methods: In Yudit, .kmap ("keymap") files with names
like Arabic.kmap, Dutch.kmap and Hungarian.kmap provide the mapping
between the key or keys physically typed by the user and the
desired Unicode character(s) to be inserted in the edit buffer.
Each .kmap file defines an Input Method, and almost 100 .kmap files
are supplied with the Yudit download.
Yudit users can switch among the input methods at will to
facilitate entering text in multiple languages/scripts, even within
the same document. Users can also define their own .kmap files to
handle new exotic scripts or simply to define new entry methods
that satisfy their own needs and tastes. For a single script,
e.g. Arabic, Chinese, Esperanto or Hangul, there may be different
kmap-defined input methods that appeal to different users. For
example, Yudit comes supplied with three different .kmap files for
Arabic input:
Arabic.kmap
ArabicTranslit.kmap
ArabicKeyboard.kmap
and you might not like any of them. That's OK, because it is
fairly simple to write your own .kmap file.
Writing a New .kmap File
To write a new .kmap file, the user should first study the Unicode
character implementation of the target script to determine the full
set of Unicode values that need to be entered. For a Roman-based
script like Esperanto, most of the characters are standard lower
ASCII Roman and need no special handling; you type 'b' in Yudit and
a 'b' gets inserted into the buffer. But Esperanto orthography has
six oddly accented letters that need to be entered via a
.kmap-defined input method. The six letters can be uppercase or
lowercase, resulting in 12 separate characters, and these
characters are defined in Unicode. For example, Esperanto
orthography includes a 'c' letter with a circumflex accent. The
Unicode codepoint for the lowercase version is 0x0109, and the
codepoint for the uppercase version is 0x0108. In the Unicode
specification, these are listed as
Codepoint Official Unicode Name
0x0108 LATIN CAPITAL LETTER C WITH CIRCUMFLEX
0x0109 LATIN SMALL LETTER C WITH CIRCUMFLEX
As there is no key on the ASCII keyboard for entering either of
these characters directly, the most obvious solution is to enter
them using multiple keystrokes. The basic syntax of each entry in
the .kmap file is
" InputKeystroke(s) = OutputUnicodeCharacter(s)" ,
surrounded by double quotes and terminated with a comma. Spaces
around the equal sign and between the symbols are optional and are
ignored if present. (Such spaces can improve the human readability
of the file.) The format of these entries will be discussed in
detail below.
The Esperanto.kmap file supplied with Yudit includes the following
straightforward entries. [The terminating commas do not appear to
be absolutely necessary to the current parser, but technically they
should be present.]
"cx = 0x0109" , // LATIN SMALL LETTER C WITH CIRCUMFLEX
"Cx = 0x0108" , // LATIN CAPITAL LETTER C WITH CIRCUMFLEX
"CX = 0x0108" , // LATIN CAPITAL LETTER C WITH CIRCUMFLEX
The InputKeystrokes are 8-bit values, entered either as printable
letters like c and x (as in this example) or by their numerical
ASCII values (see formats and special cases below). The output
characters are 16-bit Unicode values, notated 0xHHHH, where H is a
hex digit 0 to F. These entries have optional comments starting
with // and continuing to the end of line.
When the Esperanto entry method compiled from this source file is
selected and the user types c followed by x, the sequence of these
two keystrokes will be detected and intercepted by the input
method, and a single Unicode character 0x0109 will be inserted into
the edit buffer. (And if a suitable font is installed, Yudit will
render the appropriate glyph on the screen.) Similarly, if the
user types big C followed by either little x or big X, then the
sequence will be intercepted and mapped into a single 0x0108
Unicode character. Thus multiple input keystrokes can be mapped to
a single Unicode character, and there can be multiple sequences
that map to the same Unicode character.
Input keystroke sequences should be chosen with care to avoid
ambiguity and clashes; for human convenience, the input sequences
should also be maximally mnemonic.
The choice of "cx" is a very suitable sequence for Esperanto entry
of c-with-circumflex because
1. The letter x is not normally used in Esperanto orthography, and
2. There is already a well-known convention for typing Esperanto
that uses "cx" for c-with-circumflex when the real letter is
not available.
However, there are other conventions for typing Esperanto, and some
other user might prefer to define a slightly different Esperanto
kmap file to satisfy their own taste and habits. The following
entries, for example, could be put into a different EsperantoB.kmap
file, or even added to the original Esperanto.kmap file.
"c^ = 0x0109" , // LATIN SMALL LETTER C WITH CIRCUMFLEX
"C^ = 0x0108" , // LATIN CAPITAL LETTER C WITH CIRCUMFLEX
If such entries were defined, the typing c followed by ^ would
result in Unicode character 0x0109 being inserted in the buffer.
Similar for C followed by ^.
The mappings can also be one-InputKey-to-one-UnicodeCharacter, and
this is very common with keymaps for non-Roman scripts. Arabic has
a letter named siin that sounds like 's' and one named raa' that
sounds like 'r'. In ArabicTranslit.kmap, which as its name implies
is based on a Roman transliteration, one finds the following
straightforward one-to-one mappings.
"s = 0x0633" , // type 's', get Unicode Arabic siin character
"r = 0x0631" , // type 'r', get Unicode Arabic raa' character
(In this case and elsewhere, one must study the Unicode
documentation to see what the Unicode codepoint values are; in this
case, you simply have to look up the information that Arabic siin
has value 0x0633 and Arabic raa' has the value 0x0631. The Unicode
charts for Arabic and other languages are easily examined starting
from http://www.unicode.org/charts/)
An Arabic keymap like this one, covering a whole Roman
transliteration system, would appeal only to those people who know
and like that particular transliteration. Those who prefer a
different transliteration should define their own keymap. The only
formal restriction for a new transliteration is that it be
unambiguously mappable into proper Arabic Unicode characters.
Other people entering Arabic might already be used to the keyboard
layout on the PC or the Mac, and they might prefer to define
keymaps that correspond to their favorite keyboard layouts (rather
than to some kind of Roman transliteration).
It is also conceivable that one (or multiple) input keystrokes
could be mapped to multiple Arabic Unicode characters. For
example, the Arabic sequence of characters laam followed by a bare
'alif character is properly and preferably encoded in a file or
buffer just like that, as 0x0644 (laam) followed by 0x0627 (bare
'alif). One can therefore simply type laam, followed by 'alif, but
suppose that some user preferred to think of them as a unit and
preferred to enter them together with a single keystroke, say X.
In such a case, the following one-to-many entry in a .kmap file
would be appropriate:
"X = 0x0644 0x0627" , // type just X to enter laam followed by 'alif
Remember that Unicode makes a distinction between the key(s) typed,
the Unicode character(s) encoded, and the glyph(s) rendered.
Whether the user chooses to type laam followed by 'alif, or both at
once using the shortcut defined just above, the Unicode characters
inserted into the file or buffer should be the same. Unicode
doesn't care how you _enter_ the characters--it simply defines what
the encoded file should look like.
Arabic orthography requires that laam followed by 'alif be
_rendered_ together, and all Arabic fonts supply special glyphs for
rendering the laam-'alif sequences. But the font-and-rendering
considerations are altogether separate from the entry and encoding,
and in a properly set up Arabic-capable system, the user should not
have to worry about the rendering.
Converting .kmap Files to .my Files
.kmap files are the human-edited and human-readable _source_ files
for keyboard mappings. Yudit, however, really works with .my
files, which must be generated from the .kmap files.
Study some of the .kmap files provided with the yudit release. By
default, the yudit installation "prefix" is /usr, and the yudit
executable is installed in <prefix>/bin/yudit, which by default is
/usr/bin/yudit. The .kmap source files are stored in
<prefix>/share/yudit/src/ and the .my files for the whole site are
stored in <prefix>/share/yudit/data/. (During installation, the
'prefix' variable may be modified manually, in which case the
relevant bin and share directories may be somewhere other than
/usr, which is the default prefix.)
Files with names like Esperanto.kmap and Georgian.kmap are source
files, written using any convenient text editor. To be used by
Yudit, an .my file must be generated from the .kmap source file
according to the following example, using the 'mytool' program
supplied with Yudit. Let's assume that we have just written
Georgian2.kmap to define a new input method for Georgian.
$ mytool -type kmap -kmap Georgian2.kmap -rkmap Georgian2.kmap -write Georgian2.my
If this new input method is intended only for private use by one
user, then the user should copy the Georgian2.my file to the
directory ~/.yudit/data/, i.e. to the directory named 'data', under
the directory named ".yudit", which is in the user's own home
directory.
If the new entry method is intended for your whole site, then copy
it to <prefix>/share/yudit/data/, which by default is
/usr/share/yudit/data/.
More Detail on the Syntax of .kmap Files:
Comments: Comments in .kmap files start with // and continue to the
end of line. The sequence // is therefore "special" to the parser.
It's a good idea to comment each entry.
Mapping Entries: There can be only one entry (mapping) to a line.
Each entry must be surrounded by double quotes. Technically, each
entry should also be terminated with a comma.
Each entry is of the form:
" InputSymbol(s) = OutputSymbol(s) " ,
where the Input is one or more 8-bit ASCII keystrokes, represented
as printable ASCII characters, or as octal, decimal or hexadecimal
numbers. Eight-bit hexadecimal numbers are represented as 0xHH,
where H is a hex digit from 0 to F. Octal-format numbers start
with \0, e.g. \037. The Input and Output symbols are separated by
an equal sign. The Output consists of one or more 16-bit _Unicode_
characters, each represented as 0xHHHH, where H is a hexadecimal
digit 0 to F. Spaces around the equal sign and between symbols are
ignored.
From the point of view of the Input Method, the Input Symbols are
keystrokes coming from the user; the Output Symbols are the Unicode
characters to be inserted into the Yudit edit buffer.
The following symbols are "special" inside .kmap files and require
special attention:
" double quotes (used to surround an entry)
= equal sign (used to separate Input Symbols and Output Symbols)
space (ignored around the equal sign and between symbols)
+ plus sign (interpreted by default as a positive prefix to a number)
- minus sign (interpreted by default as a negative prefix to a number)
\ backslash (used to literalize a special symbol)
Th special symbols are literalized, where necessary, by preceding
them with the backslash "literalizer" symbol; e.g. \= denotes a
literal equal sign. The literal backslash itself is notated \\.
Examples:
" s = 0x0633 " , // one to one
" cx = 0x0109 " , // many to one
" \= = 0x0109 " , // type a literal equal sign to input 0x0109
" \\ ~ n = 0x00f1 " , // allow LaTeX-like input of n-with-tilde;
// the user types literal \ then ~ then n
" \\ \" a = 0x00E4 " , // allow LaTeX-like input of a-with-dieresis;
// the user types literal \ then literal "
// then a to input Unicode a-with-dieresis
// (a with two dots above)
" \+u = 0x00FC " , // user types literal + followed by u
// to input 0x00FC, which is u with dieresis
// (two dots above)
" X = 0x0644 0x0627 ", // one to many
" 0x32 = 0x0662 " , // type ASCII '2' get ARABIC-INDIC DIGIT 2
Literal double quote: Each whole entry is surrounded by double
quotes, so the double quote is "special" in .kmap files. A literal
double quote can be included inside an entry by typing \", where
the backslash is the escape or "literalizing" character. Another
way to indicate a literal double quote is to give its 8-bit lower
ASCII value, e.g.
" \\ 0x22 a = 0x00E1 " , // 0x22 is the literal double quote symbol
Literal backslash: To indicate a literal backslash as input, use \\
or indicate the 8-bit ASCII numeric value.
" \\ \" a = 0x00E4 " , // \\ denotes a literal backslash symbol
" 0x5c 0x22 a = 0x00E1 " , // equivalent to the entry just above
Similarly, the equal sign separates the Input and Output; where
necessary, a literal input equal sign is indicated as \= or \0x3D.
" \= = 0x2345 " ,
" 0x3D = 0x2345 " , // 0x3d is the literal equal sign
The + and - can are interpreted by default by the parser as part of
a numerical value, so if they are intended as literal input, then
they should be literalized in the usual ways, as in this example
from Georgian.kmap
"\+z = 0x10df " ,
or using the ASCII value of the plus sign (0x2B)
" 0x2b z = 0x10df " ,
Literal white spaces: Whitespace between between characters in a
kmap entry are normally ignored; this allows you to space out the
input sequences for better human readability. To notate a literal
space as part of the Input, literalize it with a preceding
backslash or indicate the 8-bit ASCII value.
" \ = 0x0020 " , // space literalized with preceding backslash
" 0x20 = 0x0020 " , // 0x20 is the space ASCII value
Digits: By default a string segment that starts with a digit 0-9 is
considered a numeric value, not the literal symbols 0-9. To
indicate the input of a literal digit, indicate its 8-bit ASCII
value.
" 0x32 = 0x0662 " , // 0x32 is the ASCII value of '2'
Number formats. Input keystrokes can be notated as octal, decimal
or hexadecimal numbers, e.g. a period (full stop) could be notated
equivalently as 46 (decimal), \056 (octal) or 0x2E.
More Examples, taken from Kana.kmap:
"\033 KE=0x30F5", // SMALL KE
"\"R=0x201D", // RIGHT DOUBLE QUOTATION MARK
"kke=0x3063 0x3051",
"0x20 = 0x201D", // INPUT LITERAL BLANK
"0x3D=0x003D", // INPUT '=' SIGN THIS WAY
The // sequence is special in kmap files, being the introducer of a
comment. If you want the sequence // as part of the Input, then
the two slashes need to be separated by a space, e.g
"&/ /=0x005C", // YUDIT NEEDS SPACE BETWEEN / /
// to avoid treating // as the comment introducer
Yudit Strategy for Input Matching
Clashes: It is illegal to have the same input sequence map into two
different outputs.
// this is an illegal clash
" cx = 0x0109 " ,
" cx = 0x0108 " ,
Where multiple input sequences start with the same substring but
have different lengths, the "greedy" matching algorithm prefers
the longest match. The Esperanto mapping for c-with-circumflex
could conceivably be done as follows:
" cx = 0x0109 " , // lowercase c with circumflex
" cxx = 0x0108 " , // uppercase C with circumflex
Then if the user typed c, x, and anything but another x, the value
0x0109 would be inserted in the buffer. If the user typed c, x,
and x, then the greedy algorithm would match the longer input
sequence and insert 0x0108 into the buffer. (Such tricks are
possible, but are hardly recommended.)
Sub-translations:
"Sub-translations" are currently used only for the Yudit-supplied
Hangul-entry keymap (for Korean orthography) and for the
Yudit-supplied Unicode-entry keymap; most users don't need to know
about sub-translations. [This part of the documentation should be
reviewed and expanded. I may have completely misunderstood it.]
For entering whole Hangul characters, one can use a notation
involving "sub-translations". If the translation can be broken
down to (maximum 5) sub-translations then the first line in the
.kmap file may contain:
"string1+string2+string3...",
The subsequent lines between "begin string1", and "end string1"
contain the sub-translation lines. The resulting Unicode number is
the value of the sub-translations added up.
Sub-translation may contain empty strings
"=0x0021",
but consecutive ones cannot.
Matching strategy for sub-translations: When the first
sub-translation would match the null string, one character may be
borrowed from the previous translation.
Autoshaping information
[This section needs to be reviewed and expanded.]
The Yudit-supplied Arabic.kmap and ArabicTranslit.kmap files
contain "shaping" information, presumably for proper rendering of
Arabic. (Many special ligatures are possible in Arabic rendering,
but only the laam+alif ones are absolutely required. The following
four mysterious entries would appear to indicate the entry
sequences and Unicode value sequences that require special
rendering.)
// Shaping part using shape.mys. Autogenerated.
//
"l aM=0x0644 0x0622", // ?? LAM ALEF WITH MADDA ABOVE
"l aH=0x0644 0x0623", // ?? LAM ALEF WITH HAMZA ABOVE
"l aB=0x0644 0x0625", // ?? LAM ALEF WITH HAMZA BELOW
"l a=0x0644 0x0627", // ?? LAM ALEF
//
// End of shaping part. Autogenerated.
//
Gaspar [2003-01-21] clarifies that this section was auto-generated
by bin/arabickmap.pl, and
"bin/shape.pl generates a shape.mys shaper map that is responsible
for Arabic/Syriac shaping. As Yudit is a plain text editor, it
needs to know the obligatory ligatures, the ones that definitely
should go into one box. Those four ligatures in the example are
the obligatory ligatures.
"Please note: in fact in yudit 2.7.+ you don't need to have it
because additional characters and diacritics will automatically be
added to form a ligature, so in fact the aforementioned ligature
can be entered by simply inputting the components."
[end of quotation]
As I interpret this, Arabic kmap files can now be written without
these four mysterious lines; when the user types laam followed by
some variety of 'alif letter, the appropriate ligature glyph should
be displayed automatically. [This section subject to correction.]
Generic .mys Source Text-Conversion Files [for the future]
[This section needs to be reviewed and expanded.]
This document describes the format for .kmap files, which are
converted into .my files.
The generic .mys source files provide a few more features than the
standard .kmap files, and the .mys format will someday be
recommended as a source format for new kmap files.
The only documentation currently available for .mys files is in the
Yudit download:
http://www.yudit.org/download/yudit-2.7.2/mytool/mys/example.mys
Better documentation will be required before the average user can
understand and use .mys files.
If you need a keymap file for SMP (Supplementary Multilingual
Plane) all you can use is mys format.
Take a look at the source mys file in Yudit source tree:
yudit-2.7.8/mytool/mys/OldItalic.mys
You can compile OldItalic.mys with
mytool -convert my -write OldItalic.my -mys OldItalic.mys
Gaspar Sinai <gaspar (at) yudit.org> Tokyo 2006-05-21
Gaspar Sinai <gsinai (at) yudit.org> Tokyo 2001-01-11
Edited and augmented: ken.beesley (at) xrce.xerox.com 2003-02-06



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}